
대학원 논문으로 포털의 의제 설정 기능에 대한 주제를 다룰까 하고 관련 논문들을 정리하고 있는데 저장 용도로 공유합니다. 계속 업데이트하겠습니다. 참고할 만한 좋은 논문이 있으면 추천해 주시면 고맙겠습니다.
1. 유봉석, 김정환 (2017). 건강한 뉴스 생태계를 위한 네이버의 실험. 관훈저널, 144, 39- 47
네이버 전무 유봉석(2017) 등은 2017년 관훈저널 기고에서 언론과 네이버가 공생적 보완 관계라고 주장하면서 한국에서의 네이버와 뉴스 생산자의 협업 모델이 해외보다 앞서 있다고 평가했다.
미국에서 뉴스미디어연합(NMA)가 구글과 페이스북 등에게 콘텐츠에 대한 정당한 대가를 지불하라고 요구하고 있고 사용자들에게 유료 기사의 구독료를 받는 모델을 검토하고 있는 등 공짜 뉴스에 대한 인식과 뉴스 기업의 콘텐츠 유통 전략이 달라지고 있는 것은 사실이다.
2. 채영길, 유용민 (2017). 네이버 다음 모바일 포털 뉴스 플랫폼의 19대 대통령 선거기사 분석. 사이버커뮤니케이션학보, 34(4), 195-242
채영길(2017) 등이 네이버와 다음 등 포털 뉴스 플랫폼의 19대 대통령 선거 기사를 분석했더니 네이버와 다음의 기사 배치에서 상당한 차이를 드러냈다. 두 포털 모두 연합뉴스와 뉴시스, 뉴스1 등의 통신사의 노출이 압도적으로 많았지만 네이버는 경제지들이 상위에 포함됐고 다음은 CBS와 JTBC, SBS 등 방송사들의 노출이 많았고 네이버와 비교해서 한겨레와 경향신문, 오마이뉴스 등 진보적 성향의 매체의 노출도 상대적으로 더 많았다.
노현주 등은 네이버가 전통적 매체에 비해 중립적이고 다양성이 있다는 분석 결과를 내놓기도 했다.
뉴스 제목의 의미 연결망을 분석한 결과 네이버는 안철수와 문재인이 비슷한 정도로 언급됐지만 다음은 문재인이 안철수에 비해 훨씬 높은 빈도로 등장했다.
이 연구는 특별히 뉴스의 중심어 빈도를 비교하고 뉴스 제목의 의미 연결망을 분석했다. 데이터 스크레이퍼를 이용해 4월17일~5월8일까지 22일 동안의 기사 973건을 수집했다. 중심어는 형태소 분석한 결과를 빈도 순으로 정리한 것이고 의미연결망 분석은 유의미한 키워드 50개를 선별해 동시출현 기반 네트워크를 작성하고 Ucinet 6과 NodeXL를 활용해 분석 및 시각화한 것이다.
그 결과 네이버에서는 안철수가 문재인보다 더 많이 중심어로 노출된 것으로 나타났다. 의미연결망 분석에서도 네이버는 ‘여론조사’와 ‘TV토론’ 등 경쟁 구도가 부각된 반면, 다음은 ‘안보’와 ‘일자리’, ‘정책’ 등의 이슈 관련 키워드가 좀 더 네트워크에서 큰 비중을 차지했다.
3. 김대원, 김수원, 김성철 (2014). 네이버 뉴스스탠드 도입 이후 뉴스 웹사이트 네트워크 구 조 분석. 사이버커뮤니케이션학보, 31(4), 57-96
김대원(2014) 등은 네이버가 뉴스스탠드 서비스를 도입한 이후 뉴스 유통 구조가 어떻게 바뀌었는지를 분석했다.
이 연구에서는 웹사이트 분석 업체 랭키닷컴의 데이터를 활용해 190개 뉴스 사이트의 유입과 유출 트래픽을 분석하고 중심성과 근접 중심성, 매개 중심성, 위세 중심성 등의 지표를 측정했다. 연구 결과 뉴스 사이트의 포털 의존도가 최대 95.3%에 이르는 것으로 나타났다. 이 연구에서 몇 가지 유의미한 분석 결과로는 첫째, 경제지들이 스포츠와 연예 전문 계열 매체들로부터 트래픽을 얻는 군집 효과가 확인됐다는 것, 둘째, 조선일보 유용원의 군사세계처럼 기자 개인 블로그가 상당한 수준으로 매체 영향력을 높일 수도 있다는 사실, 셋째, 페이스북이 이미 조선일보와 동아일보 수준의 위상을 확보하고 있다는 사실, 다만 소셜 미디어는 뉴스 소비의 유출보다는 유입 중심으로 이뤄지고 있는 것으로 확인됐다. 소셜 미디어를 통해 뉴스 사이트로 옮겨가기 보다는 뉴스 소비 이후 소셜 미디어로 옮겨오는 흐름이 나타난다는 것이다.
이 연구의 한계는 랭키닷컴이라는 표본 중심의 트래픽 분석을 활용했기 때문에 표본 수가 작은 언론사의 경우 크게 신뢰하기 어렵다는 것, 그리고 뉴스 소비가 모바일로 옮겨가는 시대에 PC 중심 트래픽 분석이 갖는 한계도 있을 수 있다.
앞서 김사승 등의 연구에서는 포털 뉴스의 권력 현상을 분석한 바 있다.
4. 김경희, 송경재 (2018). 누가 2위 포털인 다음 뉴스를 이용하는가?. 한국언론학보, 62(6), 141-164
김경희(2018) 등은 네이버 기사 배열 공론화 포럼에서 한국언론학회에 의뢰해서 실시한 설문조사 결과를 활용해서 다음 이용자의 특성을 분석했다. 분석 결과 2위 포털인 다음을 이용하는 이용자들이 상대적으로 여성보다 남성이 많았고 연령도 더 높은 것으로 나타났다. 네이버 뉴스보다 다음 뉴스 이용자가 진보적 성향이었고 여당 지지자가 많았다. 상대적으로 다음이 외부의 영향에서 자유롭다고 믿고 포털이 상대적으로 개별 언론사보다 더 중립적이라고 믿는 이용자도 많았다.
5. 박대민 (2013). 뉴스 기사의 빅데이터 분석 방법으로서 뉴스정보원연결망분석. 한국언론학보, 57(6), 234-262
박대민(2013)은 NSNA(news source network analysis, NSNA) 기법을 활용해 뉴스에 등장하는 정보원을 분석했다. 연구 결과보다 방법론적 접근에서 더 의미 있는 연구라고 할 수 있다.
NSNA는 자료 수집과 정형화, 분석 및 시각화의 3단계로 진행된다. NLP 등을 거쳐서 기사를 정형화된 자료로 변환하고 SNA를 활용해 연결망과 중앙성 값 등을 도출한 다음 정보원을 클러스터링하고 인용문과 기사 등을 시각화하는 방법이다.
실제로 박대민은 2012년 1월 17일~7월 16일까지 20개 매체의 기사 619,328건의 기사를 크롤링한 다음 ‘뉴타운’이라는 단어가 들어간 기사 2,239건을 대상으로 정보원과 인용문을 추출했다. 그 결과 개인이면서 실명으로 등장하는 정보원은 321명이었고 인용문은 1100건이었다. 연결 정도 중앙성이 가장 높은 정보원은 박원순, 박원갑, 박상언, 함영진, 양지영 순으로 집계됐다.
6. 감미아, 송민 (2012). 텍스트 마이닝을 활용한 신문사에 따른 내용 및 논조 차이점 분석. 지능정보연구, 18(3), 53-77
감미아(2012) 등은 신문의 논조 차이를 분석하기 위해 텍스트 마이닝 기법을 활용했다. 카인즈에서 3026건의 기사를 수집했고 Lucene Korean 모듈을 이용해 자연어 처리를 하고 네트워크 지도를 만들었다.
연구자가 직접 코딩을 할 경우 연구자의 가치 판단에 따른 오류가 있을 수 있지만 텍스트 마이닝 기법을 활용하면 방대한 데이터를 분석할 수 있다. 이 연구는 다량의 데이터를 분석할 경우 막연하게 생각돼 왔던 신문사별 논조 차이를 입증할 수 있는지 확인하는 데 있다. 구체적으로 단순 빈도의 분석과 네트워크 시각화의 차이를 비교한 것도 이 연구에서 중요한 지점이다.
7. 양혜승 (2018). 포털과 지역혐오 : 네이버 범죄뉴스의 지역혐오댓글에 대한 내용분석. 한국언론학보, 62(6), 7-36
양혜승(2018)이 2017년 포털 사이트 범죄 뉴스에서 지역 혐오 댓글의 유형을 분석한 결과 범죄 뉴스 687건의 기사에 달린 댓글 20,419건 가운데 지역 혐오 댓글이 850건, 전체의 4.16%인 것으로 나타났다. 특히 이 가운데 64.4%가 전라도 지역을 대상으로 한 것이었다.
이 논문에서는 체계적 표집(systematic samplig) 방식으로 8일 간격으로 요일을 고르게 배분하면서 46일의 날짜를 선정하고 네이버 뉴스의 사건사고 섹션에서 강력 범죄와 절도 범죄, 폭력 범죄 관련 기사를 모두 수집했다. 흉악 범죄만 분석하기 위해 지능, 마약, 교통 등의 범죄 관련 기사를 배제했고 연예인이나 스포츠 선수 관련 뉴스도 제외했다.
이 연구에서 눈여겨 볼 대목은 지역 혐오 댓글 가운데 해당 지역이나 지역 주민에 대해 부정적인 고정 관념을 언급하는 스테레오타이핑 유형의 댓글이 가장 많은 것으로 나타났다는 대목이다. 전라도 지역에 대한 혐오 댓글의 경우만 놓고 보면 지역 단순 명기와 조롱하기 유형이 상대적으로 높은 비율을 차지했다.
8. 유수정 (2018). 포털에서 유통되는 단독 보도의 유형에 대한 탐색적 연구. 한국언론학보, 62(3), 68-97
유수정(2018)은 2017년 9월11일부터 24일까지 2주 동안 네이버 뉴스에서 단독이라는 키워드로 검색한 기사 2501건 가운데 단독 보도라는 의미로 제목에 단독이라는 단어가 포함된 기사 778건을 추출해 분석했다. 이 분석 결과에 따르면 제목에만 단독이라는 표현이 있고 본문에는 없는 경우가 466건, 59.9%로 나타났다. 공개된 정보를 단독으로 다뤘다는 의미에서 단독이라는 표현을 쓴 경우가 55.7%, 단독으로 입수했다는 의미가 22.5%, 단독으로 발굴했다는 의미의 기사가 14.0%로 각각 나타났다.
이 연구 결과에서 중요한 지점은 단독이라고 주장하는 기사가 실제로 기사를 읽어도 단독인지 아닌지 알기 어렵고 제목에서 주장하는 것 이외에 실제로 독자가 기사의 독보성을 알 수 없다는 문제를 지적한 대목이다. 유수정은 이 연구에서 포털에서의 단독의 남용이 일상적인 취재 활동을 단독으로 둔갑시켜 단독이라는 권위를 스스로 무너뜨릴 위험이 크다고 경고했다.
9. 송해엽, 양재훈 (2017). 포털 뉴스 서비스와 뉴스 유통 변화. 한국언론학보, 61(4), 74-109
송해엽(2017) 등은 2000년 4월부터 2017년 2월까지 웹 스크레이핑 기법으로 네이버에서 유통된 뉴스 80,428,892건을 수집해서 뉴스의 공급량과 집중도 등을 분석했다.
네이버에 공급된 뉴스는 2003년 3월 월 10만 건을 넘기 시작해 2005년 3월 20만 건을 넘었고 2006년부터 연합뉴스와 뉴시스 등 통신사들이 합류하면서 크게 늘어났다. 2007년 7월 월 30만 건을 넘어섰고 스포츠 연예 기사가 종합지 기사 수를 넘어선 게 2010년이다. 2013년에는 종합편성 채널이 합류하면서 월 70만 건을 넘어섰다. 2015년 10월이 월 93만여 건으로 최고점을 기록했다. 이후 포털 제휴평가위원회가 도입되면서 어뷰징 기사가 줄고 기사 건수가 감소하는 추세다. 분야별로는 경제 기사가 20.9%, 사회 기사가 22.5%를 차지했고 연예가 15.7%, 스포츠 기사가 11.7%를 차지했다.
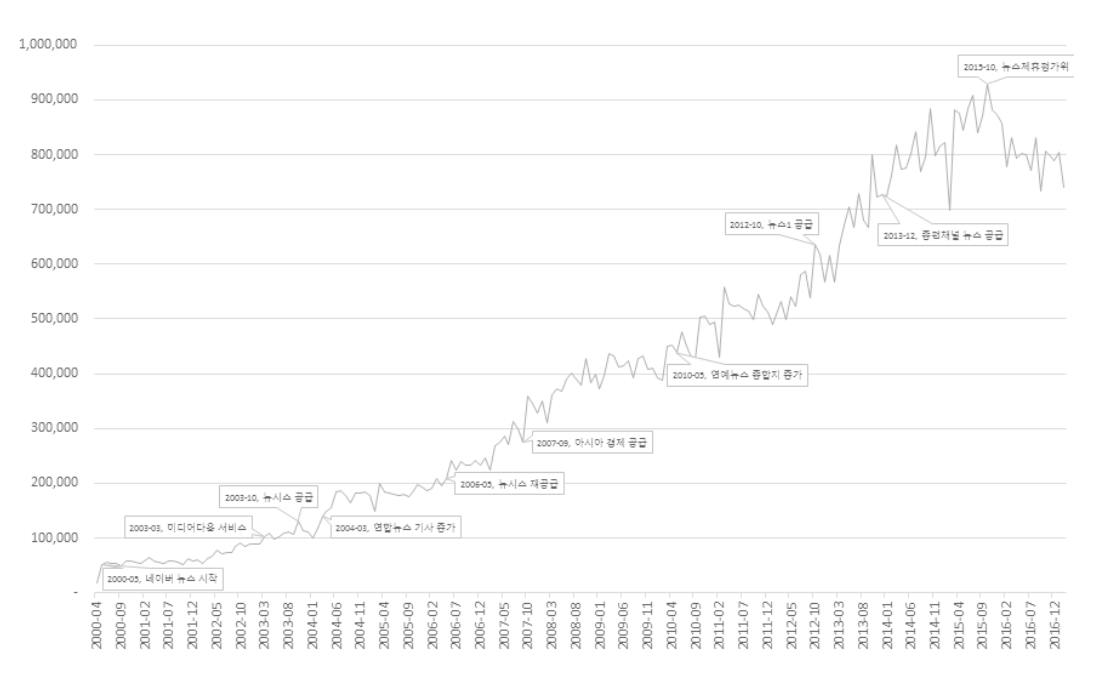
이 논문은 광범위한 기간의 기사 유통 현황을 파악할 수 있다는 점에서 흥미롭지만 기사 출고 건수를 기준으로 집중도 등을 분석하는 것이 옳은 방식인지 의문이다. 당연히 단신 속보와 후속 보도 중심의 통신사들은 기사 출고 건수가 많을 수밖에 없다. 기사 출고 건수가 늘어난 것은 기사를 공급한 언론사가 늘어났기 때문이다. 논문에도 언급돼 있지만 기사 출고 건수를 비교할 때는 각각의 언론사들이 기사 공급 기간이 다르다는 사실도 감안해야 한다. 조선일보와 중앙일보는 각각 최근 6개월과 1년여 정도의 기사만 아카이브에 남아있는 상태다. 연예 스포츠 기사가 늘어난 것은 사실이지만 애초에 기사의 유형이 다르기 때문에 연예 기사가 많다고 해서 뉴스가 연성화되고 있다고 보기는 어렵다.
10. 송해엽, 양재훈, 오세욱 (2020). 포털 뉴스 발행시간을 통해 본 언론사 뉴스 생산 관행 : 2000년 부터 2017년까지 네이버 뉴스 데이터에 대한 탐색적 분석. 한국언론학보, 64(2), 184-216
송해엽(2020) 등은 역시 웹 크롤링 방식으로 2000년 2월부터 2017년 3월까지 네이버 뉴스 섹션의 뉴스 80,427,892건을 수집하고 이 가운데 종이신문을 보유하고 있는 언론사와 비교 대상으로 통신사 기사만 추려서 49,784,412건을 대상으로 발행 시간을 분석했다. 분석 결과 과거에 지면 중심으로 기사를 작성하던 언론사들이 포털의 영향력이 높아지면서 포털을 기사의 유통 채널로 활용하고 있다는 사실을 확인할 수 있었다. 2004년부터 오전 9시부터 11시 사이 오전 시간에 기사 송고 비율이 늘어나기 시작한 것으로 확인됐다.
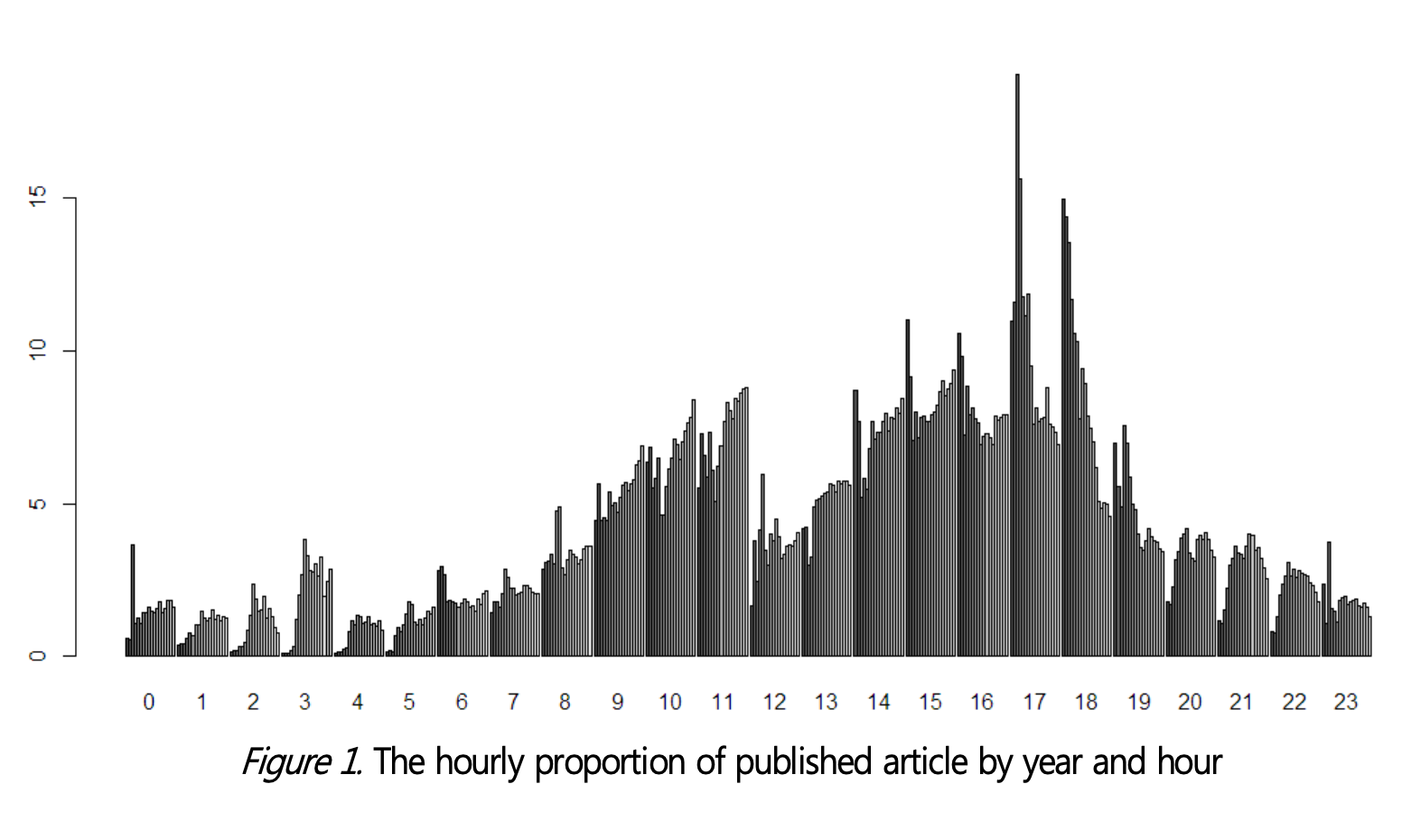
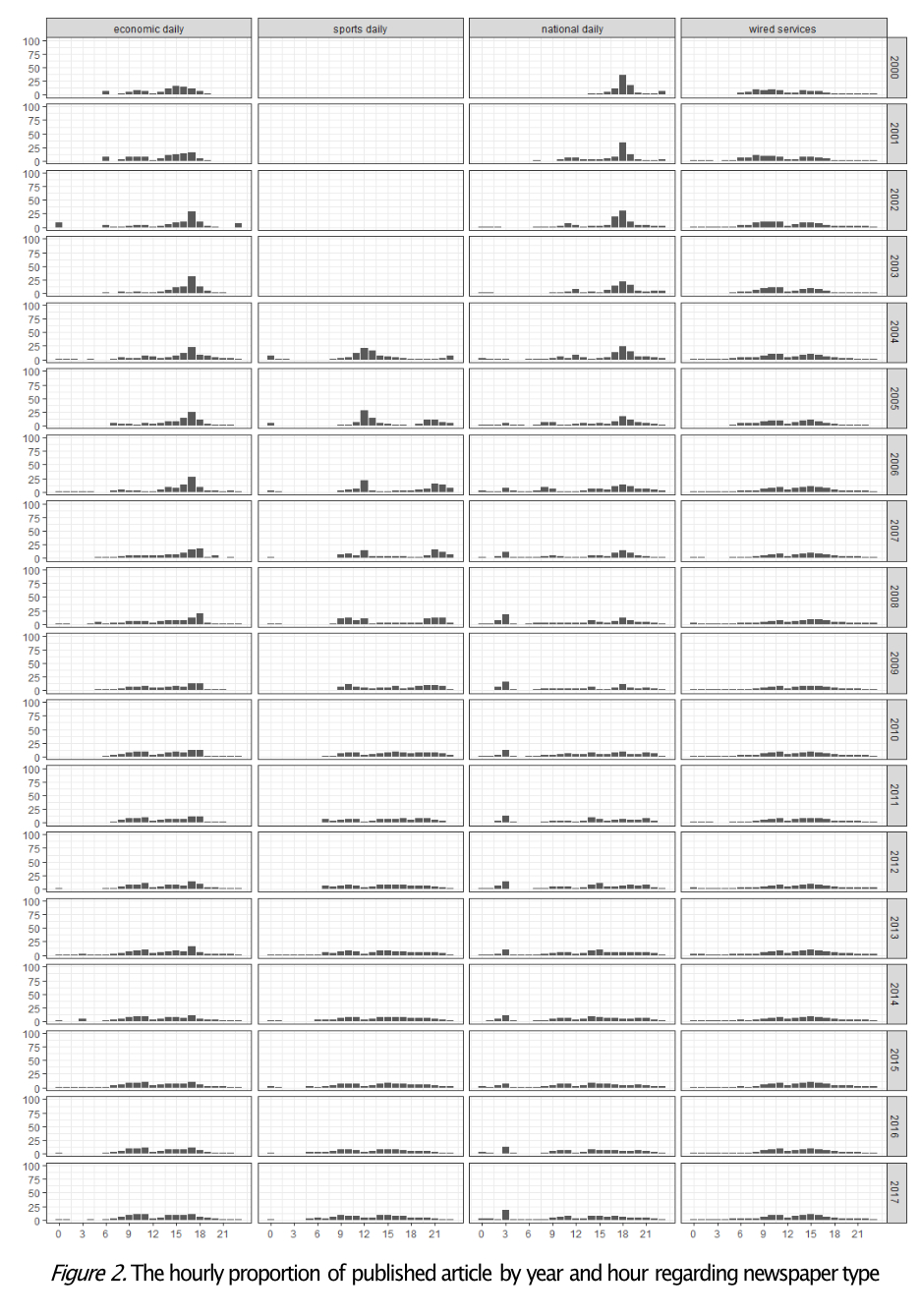
2017년 기준으로 살펴보면 저녁 21시에서 자정사이에 기사를 입력하는 비중이 여전이 20%나 되지만 13시에서 17시 사이에 송고하는 비중도 25%를 차지하는 것으로 나타났다. 포털 초기에는 18시에서 20시 사이에 기사를 송고하는 경우가 대부분이었지만 최근에는 낮 시간에 발행하는 비율이 늘어나면서 전체적으로 M자형 패턴을 나타낸다는 분석이다.
조사와 별개로 문헌 연구를 실시했는데 언론 종사자 수가 2000년부터 2012년 사이에 11% 늘었지만 발행 기사 건수가 498.6% 늘어났다는 사실도 흥미롭다.
11. 이현진, 이승우 (2018). 사회적기업 인식에 관한 연구: 네이버 트렌드 데이터를 활용하여. 사회적기업연구, 11(1), 51-74
이현진(2018) 등은 네이버 트렌드를 활용하여 사회적 기업과 일자리의 상관 관계를 분석한 바 있다. 구직, 구직난, 일자리, 취업, 취업난, 취직, 취직난 등의 키워드와 저소득층, 고령자, 장애인, 경력단절 여성 등 취약계층의 키워드를 하위 검색어로 포함시켜 교차 상관 분석(cross correlation analysis)과 그랜저 인과 검정(granger causality)을 진행했다.
연구 결과 여성의 경우 일자리 문제와 사회적 기업의 관계를 연관지어 생각하는 경향이 상대적으로 높지만 남성의 경우 일자리 문제와 사회적 기업의 관계를 인식하는 정도가 낮은 것으로 나타났다.
그러나 이 논문에서 지적하고 있듯이 네이버 트렌드 데이터는 상대적인 수치만 제공할 뿐 검색량의 절대적 수치를 말해주지는 않는다. 2016년 1월1일부터 2017년 10월18일까지로 기간이 한정돼 있어 데이터의 왜곡이 발생할 가능성도 배제할 수 없다.
12. 이완수, 최명일 (2020). 범죄뉴스 헤드라인 언어와 의미구성 : 포털 사이트 ‘네이버’에 보도된 범죄 유형별 의미연결망 분석을 통해. 한국언론정보학보, 101, 367-398
이완수(2020) 등은 포털 뉴스의 범죄 기사에 등장하는 핵심어를 분석하기 위해 2014년 7월1일부터 2016년 6월30일까지 2년 동안 사회 분야 뉴스 상위 30위 기사 가운데 범죄 뉴스를 선별하고 유형을 분류했다.
이 연구에서는 팔달산 토막 살인 사건과 원영이 학대 사건 등의 사건을 선별한 다음 전체 기사를 수집해서 헤드라인을 분석하고 형태소 분석기 Espresso K를 이용해서 빈출 단어를 추출했다. 빅데이터 분석 업체 텍스톰의 솔루션을 활용해 UCINET와 Netdraw를 이용해 연결 정도 중심성과 군집 분석을 실시하고 시각화했다.
분석 결과 범죄 보도에서 살인범이나 가해자에 초점을 맞춘 보도가 주를 이루고 범죄 행위의 잔인함과 엽기성, 특이성 같은 자극적이고 선정적인 부분을 부각시킨 것으로 나타난 반면 종합적이고 체계적인 접근이나 분석을 통해 재발 방지나 예방에 초점을 맞춘 보도는 거의 찾아볼 수 없었다는 게 이 논문의 결론이다.
다만 여러 기사의 헤드라인에 자주 등장하는 단어가 실제로 기사의 논조를 제대로 반영하는지는 의문이다. 팔달산 사건의 경우 용의자, 시신, 피의자, 범행,수원, 범행, 공개 등의 단어가 연결 중심성이 높은 것으로 나타났는데, 이는 연결 중심성이 아니라 그냥 빈도만 따져봐도 확인할 수 있는 사실이다. 실제로 연결 중심성 순위와 빈도 순위가 거의 일치한다는 사실도 확인할 수 있다. 하위 집단 분석 역시 살해 방법과 범죄 사실, 가해자라는 각각의 주제에 따라 관련 단어가 비슷한 빈도로 출현한다는 의미일 뿐 특별히 이 논문의 분석으로 새롭게 드러난 사실은 많지 않다.
13. 방한솔, 이근영, 문호석 (2019). 텍스트마이닝을 이용한 뉴스 언론보도 분석 방법론 연구. 한국경영과학회 학술대회논문집, 3497- 3502
방한솔(2019) 등은 텍스트 마이닝으로 토픽을 추출하고 토픽을 추출하는 방법을 제시했다. 1단계로 웹 스크래핑으로 기사를 추출한 다음, 2단계로 TF-IDF 방식으로 가중치를 부여해 핵심 단어를 선정하고 단어-문서(term-document) 행렬을 작성한다. 3단계에서는 LDA 모형을 적용해 주요 토픽을 선정하고 4단계에서는 시계열 변화를 확인했다.
사례로 제시한 연구에서는 2018년 네이버 뉴스 정치 섹션의 기사 33만여 건 가운데 제목에 ‘북핵’을 포함한 694건을 대상으로 분석한 결과, 상위 30%를 차지하는 284개의 단어를 선정했다. 이를 기초로 월별 빈도수를 행렬로 정리하고 정상 회담과 고위급 회담, 지방 선거, 비핵화 등 주요 토픽 10개를 선정했다.
이 연구는 그동안 뉴스 분석에서 연구자들의 정성적 판단에 의존하는 경우가 대부분이었다면 텍스트 마이닝과 데이터 마이닝으로 정량적 분석을 시도했다는 데 의미가 있다. 대용량의 텍스트 데이터를 토픽으로 표현하고 월별 관심도를 정량적으로 표현하고 객관적이고 합리적인 방법을고 토픽의 수를 결정했다. 대용량의 데이터를 다루면서도 주관의 개입을 최소화했다는 데 의미가 크다.
14. 김동욱, 이수원 (2017). 단어 유사도를 이용한 뉴스 토픽 추출. 정보과학회논문지, 44(11), 1138-1148
김동욱(2017) 등은 그동안 대표적인 토픽 모델로 활용했던 잠재 디리클레 할당Latent Dirichlet Allocation, LDA 방식의 한계를 극복하기 위해 LDA 방식으로 토픽을 추출한 다음 단어의 유사도를 이용해 토픽을 분리 또는 병합하는 방법으로 토픽을 보정하는 방법을 제안했다.
토픽은 명사의 집합이다. 크롤러를 통해 뉴스를 수집하고 형태소 분석을 통해 명사를 추출한 다음 유사도 기반 토픽 추출기에 입력한다.
LDA는 출현 빈도를 계산하지만 유사도를 계산하지 않기 때문에 PMI(동반출현확률, Pointwise Mutual Information)라는 지표를 활용했다. PMI는 두 단어가 한 문장에 동시에 출현할 확률에 각각 출현할 확률을 곱한 것으로 나눈 값이다. 연관성이 높을수록 PMI 값이 높다고 볼 수 있다.
이 연구에서는 PMI 값을 이용해 TC(Topic Clique)를 생성하고 TC의 거리가 짧을수록 유사도가 높은 것으로 보고 일정 거리 미만의 TC를 하나의 토픽으로 병합했다. 연구자들에 따르면 이 같은 방식이 기존의 방식보다 유의미하게 정확도가 높은 것으로 나타났다.
15. 한은진, 채혜진, 우혜원, 손소영 (2018). Word2vec algorithm 기반 뉴스 기사에 나타난 성별 관련 어휘 규명 연구. 대한산업공학회지, 44(4), 272-282
한은진(2018) 등은 주요 언론사 뉴스의 기사를 수집해 word2vec 방식으로 벡터 연산을 한 뒤 성별로 출현 가능성이 높은 단어들을 추출했다. 2014년 1월1일부터 2016년 12월31일까지 뉴스를 분석한 결과 사회 섹션 기사에서 여성과 관련된 문장이 2.26%, 남성과 관련된 문장이 1.35%로 유의미한 차이를 보였다. 전체 267,440건의 기사 4,326,835건의 문장을 분석한 결과다. 남성과 여성이 언급될 경우 관련해서 출현하는 어휘도 크게 차이가 났다.
이 논문에서는 KoNLP를 이용해 형태소 분석과 품사 태깅을 진행했고 CBOW가 아니라 Skip-gram 방법과 네거티브 샘플링 기법을 활용했다. 단어 빈도가 30개 이상인 단어들만 상요했고 주변 단어는 10개, 벡터 차원은 500으로 설정했다.
이 연구에서는 기간이 3개 년도 밖에 안 돼 시간에 따른 변화를 분석할 수 없었고 주변 단어 수와 벡타 차원 수에 따라 분석 결과에 변동이 있을 수 있다는 한계를 언급하고 있다. 최적의 설정 값을 찾는 노력이 필요하다는 이야기다.
16. 이민철, 김혜진 (2018). 텍스트 마이닝 기법을 적용한 뉴스 데이터에서의 사건 네트워크 구축. 지능정보연구, 24(1), 183-203
이민철(2018) 등은 빅카인즈에서 14만6703건의 기사를 추출하고 코모란(Komoran) 형태소 분석기를 이용해 113만5190개의 명사 토큰을 추출했다. 이 연구에서는 특별히 이형 동의어를 통합하기 위해 Word2Vec 기법을 활용했다. 그러나 이 같은 기법으로는 ‘헌재’와 ‘헌법 재판소’를 유사한 토큰으로 추출하지만 동시에 ‘대통령 탄핵 심판’도 유사한 토큰으로 분류된다는 문제가 있어 형태적 유사도(soelling similarity)와 의미적 유사도를 결합해야 한다. 이 연구에서는 9278개의 이형 동의어를 3583개로 통합했다.
이 연구에서는 사건의 관련성을 측정해 사건 네트워크를 구성했다. 2016년 12월 대국민 담화와 탄핵 소추안 발의, 촛불 집회 등이 연결된 사건이라는 사실을 확인할 수 있었다. 다만 두 사건이 관련성이 있다고 해서 인과관계가 있다고 볼 수는 없다. 2017년 김정남 암살 사건이 북한-말레이시아의 갈등으로 이어졌지만 김정남 사건이 더 오래 지속돼 인과 관계가 거꾸로 나타나기도 했다.
이 같은 연구는 방대한 양의 데이터로부터 주제와 주제의 분포를 쉽게 확인할 수 있지만 초기 파라미터에 따라 결과가 달라진다는 한계가 있다. 시간적으로 멀리 떨어진 사건이나 동일 주제에 속하는 사건 사이의 관련성 등의 연구가 필요하다.
17. 김소담, 양성병 (2015). 온라인 뉴스 사이트에서의 일반댓글과 소셜댓글의 비교분석. 한국콘텐츠학회논문지, 15(4), 391-406
김소담(2015) 등은 일반 댓글과 소셜 댓글의 차이를 비교하기 위해 2013년 8월1일부터 2014년 2월28일까지 7개월 동안 한겨레 문화 섹션의 기사 65건의 댓글 543건을 분석했다. 일반 댓글의 길이가 103.19인 반면 소셜 댓글은 88.38로 소셜 댓글이 더 짧은 것으로 나타났다. 공감도는 일반 댓글이 1.31, 소셜 댓글이 4.3으로 소셜 댓글이 좀 더 공감 지수가 높은 것으로 나타났다. 감정이나 악성 댓글 여부는 유의미한 차이를 드러내지 않았다.
이 연구는 3명의 평가자가 댓글을 나눠서 유용성과 가독성, 기사 관련성 등을 평가했는데 평가 대상이 한 신문에 한정됐고(실제로 일반 댓글과 소셜 댓글을 병행하는 언론사가 많지 않았다고 하지만) 전체 분석 대상이 543건 밖에 안 된다는 게 아쉬운 대목이다.
18. 이기창, 강필성 (2017). Graph-based representation을 활용한 뉴스 중요도 산출. 대한산업공학회 춘계공동학술대회 논문집, 5060-5081
이기창 당은 많은 언론사들이 유사한 제목의 비슷한 기사를 보도한다면 해당 사건이나 이슈는 사회에 파급력이 클 가능성이 높다는 가정으로 뉴스 제목을 꼭지점(node)로 중복 단어를 간선(edge)로 하는 무방향 그래프(undirected graph)를 생성했다. 간선이 많을수록 중요한 기사로 판단하는 방식이다. 여기에 고유벡터 중심성(eigenvector centrality)도 함께 고려해서 중요한 꼭지점에 연결된 꼭지점을 중요한 꼭지점으로 판단했다.
실험 결과 중심성이 높은 기사가 실제로 1~5면에 배치되는 비율이 높은 것으로 나타나 모델이 유의미한 것으로 확인됐다.
19. 권호천 (2017). 사드(THAAD) 관련 신문기사의 의미네트워크 분석. 언론정보연구, 54(2), 114-154
권호천에 따르면 의미 네트워크 분석(semantic network analysis)은 단어들의 연결성과 네트워크의 구조와 특징을 파악하고 텍스트가 전달하려는 의미를 분석하는 방법이다.
권호천 등은 이 연구에서 조선일보와 한겨레 지면에 실린 사드(THAAD) 관련 보도의 주요 단어와 출현 빈도, 네트워크적 특성을 분석했다. 제목과 부제에 ‘사드’가 포함된 기사를 수집했고 의미네트워크 분석 기법을 이용해 분석했다. KrKwic 기반으로 분석하는 TEXTOM의 정제 프로그램을 활용했다. 이들은 단어×단어 메트릭스를 생성해서 출현 빈도를 도출하고 네트워크 분석 프로그램인 UCINET에 적용해 연결정도 중심성과 매개 중심성 등의 네트워크 구조를 파악했다. 마지막으로 시각화를 위해 네트워크 시각화 프로그램인 넷드로(NetDraw)를 활용했다.
구체적으로 조선일보 기사 230건과 한겨레 기사 200건을 분석했는데, 주요 단어 100개를 분석한 결과 출현 빈도가 조선일보가 한겨레보다 2배 이상 높은 것으로 나타났다. 조선일보가 특정 키워드를 반복해서 사용한다는 의미로 해석할 수 있다. 한겨레가 반발, 악화, 우려, 의심 등의 부정적인 단어를 더 많이 사용한 것도 눈여겨 볼 부분이다.
그러나 연결정도 중심성과 매개 중심성은 두 신문에 큰 차이가 없었다. 클러스터 분석과 수렴 상관관계(CONCOR) 기법으로 군집분석을 실시한 결과, 조선일보 보도는 사드 도입의 필요성과 일반적 논의에 집중한 반면, 한겨레는 부정적인 견해와 이해 당사자 관계에 주목한 것이 눈에 띄는 차이었다.
다만 연구자들도 지적하고 있듯이 단순한 단어의 연결 상태만으로는 어떤 의미로 연결돼 있는지 파악하는데 한계가 있다. 지면에 드러나는 두 신문의 논조의 차이를 데이터 분석을 통해 확인했다는 데 의미가 있지만 제목과 부제만으로 내용을 분석하는 것만으로 실체적 분석이 가능할 것인지 의문이 남는다.
20. 황서이 (2020). 국내 언론을 통해 본 ‘한류’ 경향에 관한 연구 -토픽모델링과 의미연결망분석을 활용한 언론기사 분석 , 2000~2019-. 한국엔터테인먼트산업학회 학술대회 논문집, 47-57
황서이는 한류 관련 이슈와 토픽, 토픽의 관계를 분석하기 위해 토픽 모델링과 의미연결망 분석을 실시했는데, 2000년부터 2019년까지 54개 언론사 22만2528건을 분석한 결과 2005년부터 기사 수가 크게 늘어났고 2015~2016년에 정점을 지나 2017년부터는 줄어드는 것으로 나타났다.
중심성은 한류, 글로벌, 한국, 경제, 문화 등으로 나타났는데 이는 사실 누구나 예상 가능한 수준을 벗어나지 못한 결과다. 매개중심성 등도 마찬가지다. 군집 분류에서는 문화 한류와 경제 한류, 권역 및 지역, 국내외 정세, 한류 교육 등의 5개 군집으로 분류됐다.
21. 이종혁, 길우영 (2019). 토픽모델링을 이용한 뉴스 의제 분류와 미디어 다양성 분석. 한국방송학보, 33(1), 161-196
이종혁 등은 토픽모델링과 군집분석 등의 방법을 활용해 대통령 신년 기자회견 관련 뉴스 2901건을 분석했다. 네이버 검색 결과에서 언론사 이름과 날짜, 기사 제목, URL, 기사 개요 등을 크롤링한 뒤 KoNLP를 이용해 명사를 추출했다. R에 포함된 DocumentTermMatrix 함수를 이용해 문서-주제 행렬(DTM)을 작성하고 혼잡도(perplexity)를 분석한 다음 토픽 모델링을 실시했다.
토픽 모델링에서는 북한관계, 노동문제, 국민 체감, 개헌 투표, 지지율, 회견 비판 등의 8가지 의제를 추출했하고 군집 분석으로는 중립속보추구형, 진보개혁추구형, 갈등집중형, 여론민감형, 소수의제집중형, 의제종합보도형 등으로 군집을 분류했다. 군집 분석은 의제의 보도 비율을 기준으로 분류한 것이다.
분석 결과 연합뉴스는 국민 체감 의제에 가장 큰 비중을 뒀고 경향신문은 북한 관계, SBS는 위안부 합의를 강조했다. 연합뉴스와 조선일보 등은 여론민감형 군집이고 경향신문과 한겨레, JTBC 등은 진보개혁추구형 군집으로 분류됐다. 방송 3사는 의제종합보도형이었다.
이 연구는 코더의 판단 없이 대규모 용량의 기사 분석을 실시했다는 데 의미가 있다. 의제의 해석과 명명이 연구자의 주관적 판단에 의존할 수밖에 없다는 게 한계로 거론됐지만 토픽 모델링이 더욱 활성화돼야 한다는 게 이 논문의 결론이다.
22. 이희영, 김정기 (2016). 질적 메타분석을 통한 뉴스프레임의 유형. 한국언론학보, 60(4), 7-38
메타분석은 특정 연구 주제에 대해 행해진 여러 독립적인 연구결과들을 종합하는 계량적이고 통계적인 연구방법이다.
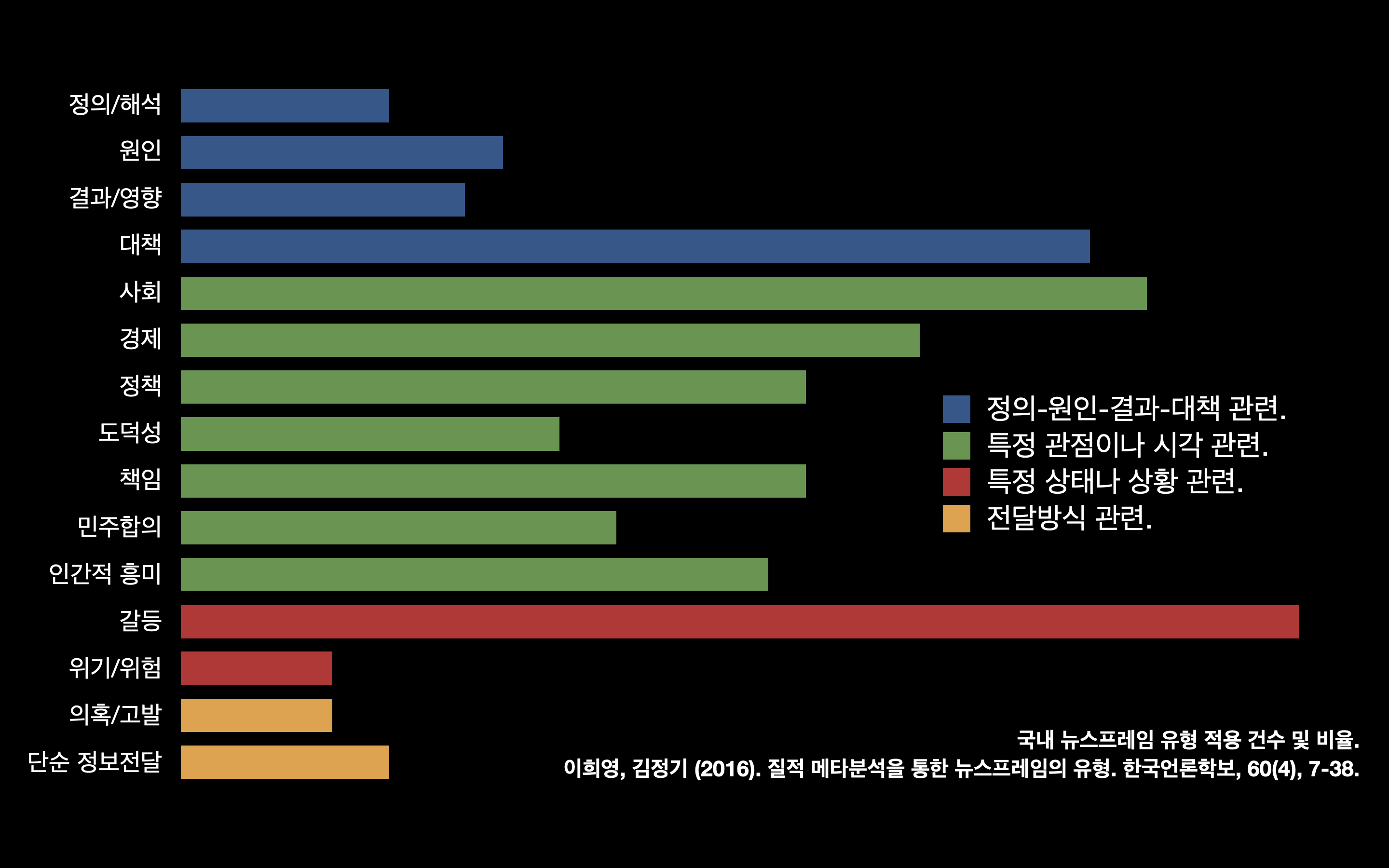
이희영 등은 뉴스 프레임에 대한 연구 논문 120편을 분석해 프레임의 유형을 분석해서 4가지 차원의 15개의 프레임 유형을 도출했다. 4가지 차원은 각각 정의/해석 프레임과 원인 프레임, 결과/영향 프레임, 대책 프레임으로 나뉜다.
질적 메타분석(meta analysis)이란 질적 연구 결과물을 통합 분석할 수 있도록 개발된 방법(나장함, 2008)으로 기존의 실증적 연구 결과를 정량적 방법을 통해 통합하는 메타분석(Glass, 1976; Glass, McGaw, & Smith, 1981)과는 구분된다.
이 연구에서는 미국과 달리 한국 언론에 정책과 민주합의 프레임이 상당한 비중을 차지하고 있다는 데 주목했다. 갈등 프레임이 가장 많이 사용된 반면 도덕성 프레임은 상대적으로 빈도가 낮다는 사실도 흥미롭다.
몇 가지 흥미로운 대목이 있지만 언론 보도를 다룬 논문을 대상으로 프레임을 분석한 결과라 실제 언론 보도의 유형이라고 보기 어렵다.
23. 하승태 (2014). 전통매체 및 인터넷 뉴스 이용과 공중의제 일치정도에 대한 고찰. 지역과 커뮤니케이션, 18(1), 307-328
하승태는 미디어 이용 수준이 높을수록 공중 의제에 대한 일치 정도가 높을 것이라는 가설을 인구통계학적인 방법으로 검증했다. 2010년 지방 선거 패널 조사 결과를 활용해 국정 과제와 미디어 주목 정도를 비교한 것이다.
이 연구에 따르면 소득이나 성별 등과 무관하게 미디어 이용수준이 높을수록 공적의제에 대한 합의 정도가 높은 것으로 나타났다. 양극화 완화와 국민 통합, 경제 성장 등의 주요 의제에 답변이 집중됐고 미디어 이용 수준이 높을수록 답변이 다양했다. 미디어의 의제설정기능이 한국의 미디어 환경에서도 충분히 적용가능하다는 의미로 해석할 수 있다. 다만 인터넷의 이용은 오히려 공적 합의를 감소시켜 공중 의제의 다양성을 확대시키는 역할을 하는 것으로 분석됐다.
흥미로운 시사점을 주는 연구지만 분석의 수준이 깊다고 보기는 어렵다.
24. 김용회, 한창근 (2019). ‘수저계급’ 관련 웹 뉴스 기사에 대한 의미연결망 분석. 한국사회복지학, 71(3), 55-81
김용회 등은 네이버 검색에서 ‘수저계급’이라는 키워드로 검색한 기사 827건을 분석했다. 빅데이터 분석 프로그램 텍스톰(TEXTOM)을 활용해 중복된 기사와 광고성 기사 등을 제거하고 명사를 추출한 다음 출현 빈도 200회 이상의 핵심 키워드 30개를 선정했다. 평균 연결 정도(Average degree), 네트워크 밀도(Network density)와 전체 네트워크 중심도(Network centralization) 등의 지표를 분석해 관련 노드들의 연결 정도를 비교했다.
이 연구에 이용된 분석 기법은 크게 세 가지다. 첫째, TF-IDF는 TF(Term Frequency: 단어 빈도)와 IDF(Inverse Document Frequency: 문서빈도의 역수)를 곱한 값이다. 어떤 단어가 특정 문서 내에서 얼마나 중요한지에 대해 가중치를 부여한 통계적 수치다. 둘째, 연결 중심성(Degree centrality)은 특정 노드가 다른 노드들과 얼마나 많은 연결이 되어 있는지를 계량화한 수치다. 연결 중심성이 높을수록 영향력이 크다고 할 수 있다. 셋째, CONCOR 분석은 동시출현 매트릭스를 통해 간접적인 연결패턴의 상관계수를 반복적으로 측정하여 적정한 수준의 유사집단을 식별해내는 분석 기법이다.
분석 결과 TF-IDF 가중치가 높은 키워드는 정책, 자산, 한국, 사회 순이었다. 연결 중심성이 큰 키워드는 금수저·흙수저, 사회, 정책, 일자리 등이었다.
UCINET 6의 NETDRAW로 시각화한 결과 수저·흙수저를 중심으로 사회, 일자리, 자산, 정책 등이 강한 연결정도를 갖는 것으로 나타났다. 정책과 서울, 경제, 일자리 등은 또 다른 차원의 연결고리를 갖고 있는 것으로 확인됐다.
덴드로그램(Dendrogram) 분석으로는 7개의 군집이 확인됐다. 각각 계급 사회와 세대 간 이동, 불평등, 부의 세습, 사회현상, 사회정책, 사회이동 등이다. 이 논문의 결론은 수저계급이라는 계층적 신분구조가 경제적 불평등 양상에서 교육, 주거, 일자리, 지역 격차에까지 중첩, 확산되어 가고 있다는 것이다.
25. 박승정, 전진오, 김선우, 김성태 (2017). 국내 주요일간지의 대통령 이슈소유권에 대한 빅 데이터 분석. 정치정보연구, 20(3), 25-55
김성태에 따르면 커뮤니케이션 연구에서 내용분석(Contents Analysis)은 물리적 콘텐츠에 대한 객관적, 체계적, 수량적 그리고 재연 가능한 방식으로 콘텐츠 자체에 관해 기술하거나 의미를 추론하기 위해 사용됐다. 콘텐츠에 내재한 의미를 구체적이고 정교하게 분석해 낼 수 있다는 장점이 있지만, 많은 시간과 노력을 필요로 하는 작업이고 분석 데이터 규모의 제약, 코더간 신뢰도, 시간 및 비용, 연구자의 주관성 개입 등 다양한 현실적인 문제가 있다.
토픽 모델링은 구조화되지 않은 방대한 문헌 집단에서 유사하게 범주화되는 주제를 찾아내기 위한 알고리즘이다(Blei 2012). 토픽모델링은 문서를 구성하고 있는 숨겨진 구조(hidden structure)와 토픽을 자동으로 추출해준다. 숨겨진 구조는 첫째, 문서 집합에 숨겨진 토픽과 둘째, 각각의 문서들이 갖고 있는 토픽들의 분포(distribution), 그리고 셋째, 문서에 쓰인 단어들이 어떤 토픽인지 등이다. 비지도 방법(unsupervised method)이라 문서에 대한 사전 지식이 없어도 해당 문서들이 가진 토픽이 무엇인지 분석하는 데 유용하다는 평가를 받는다. 토픽 모델링의 알고리즘은 샘플링 기초 알고리즘(sampling-based algorithms)과 변분추론(variational algorithms)으로 나뉜다.
LDA(latent Dirichlet allocation) 모델은 다음 세 가지 이유에서 사회과학 연구에 적합하다. 첫째, 단어는 다른 단어와의 관계 속에서 의미를 갖는다고 가정한다. 다른 단어와의 관계에서 의미가 형성된다는 접근 방식이다. 둘째, 문서나 문단에서 함께 사용된 단어의 동시 출현을 중요하게 포착한다. 중심성(centrality) 빈도가 높은 순으 로 나타나게 된다. 셋째, 하나의 문서에 여러 가지 토픽이 담길 수 있다. 하나의 텍스트가 단일한 관점만을 반영하는 것이 아니라 경쟁하는 여러 관점이 동시에 나타날 수 있다는 사회과학의 가정과 조화를 이룬다.
이 연구에서 분석한 사설은 조선일보 945건과 한겨레 1627건이다. 분석 결과 추출된 22개의 토픽은 최순실, 북핵, 경기 활성화, 인사, 국회, 야당 순이다. 조선일보가 경제 분야를 많이 다룬 반면 한겨레는 국정 교과서와 세월호, 최순실 사태 등을 더 많이 다뤘다. 김성태는 조선일보가 굵직한 토픽을 끌고 가면서 이념적 성향의 선명성을 강조한 반면 한겨레는 문제가 있는 상황을 꾸준히 제기하면서 새로운 토픽을 발굴, 보도하는 성향이 더 강했다고 평가했다.
LDA 분석의 한계를 거론하지 않을 수 없다. 문맥을 고려하지 않은 단어의 빈도만으로 복잡한 사건의 맥락과 구조를 분석한다는 게 결코 쉬운 일은 아니다. 실제로 연구 결과에 크게 의미를 두기 어려운 논문이다.
26. 노준형, 백영민 (2019). 기업 루머 이슈에서 등장하는 토픽 변화 및 위기 커뮤니케이션 과정의 담론 경쟁. 한국광고홍보학보, 21(1), 147-189
노준형 등은 기업의 루머 이슈와 관련한 토픽의 발생과 확산 과정을 살펴보기 위해 깨끗한나라의 생리대 유해 물질 논란을 추적했다. 언론 보도 1525건과 트위터 게시물 551건을 크롤링한 뒤 KoNLP를 이용해 명사를 추출했고 그리피스와 스테이버스의 알고리즘을 기반으로 잠재 토픽 수 k를 추정했다. 모형과 텍스트 데이터 사이의 적합도, 즉 로그우도(log-like- lihood, 모형과 데이터의 적합도)를 이용해 k를 115로 설정했다.
토픽을 추출하기 위해 구조적 토픽 모형(STM)을 활용했고 다음 네 가지 종류의 토픽을 분석에서 배제했다. 첫째, 토픽의 의미가 본 연구와 무관한 경우, 둘째, 추출된 단어만으로 토픽의 의미 파악이 명확하지 않거나 토픽 의미가 너무 광범위한 경우, 셋째, 토픽의 의미가 연구문제와 다소 거리가 있는 경우, 넷째, 시기별 평균 토픽 발현 확률이 매우 낮은(최소 1회 2%를 넘지 않는) 경우 등이다.
추출된 토픽은 접착제 유해성과 유해물질 공포, 생리대 환불, 국정감사, 공정성 논란 등이었다. 이슈의 흐름에 따라 급성 단계와 만성 단계, 해결 단계로 나눴는데 급성 단계에서는 부작용 확산 등의 토픽이 늘어난 반면, 만성 단계에서는 현장 조사 등의 토픽이 늘어났다. 트위터에서는 언론 보도와 달리 접착제 유해성과 실험 생리대 구입 등의 토픽의 비중이 더 컸다. 이 연구에서는 깨끗한나라가 시민단체에 실험 결과 공개를 요구하고 문제제기를 했던 교수를 검찰에 고발하면서 여론에 변화가 일어났다는 사실이 새로 드러났다.
27. 권민지 (2019). 토픽 모델링 기반 뉴스기사 분석을 통한 서울시 이슈 도출. 한국방송미디어공학회 학술발표대회 논문집, 11-13
권민지는 11개 일간신문에서 서울시로 검색한 기사 8만609건을 토픽 모델링 기법으로 분석했다. 분석 결과, 2015년에는 메르스와 병원이 핵심 토픽이었고 2016년에는 환경과 복지, 2017년에는 여성, 2018년에는 미세먼지와 택시, 2019년에는 광화문과 광장이 토픽으로 떠올랐다.
28. 김영욱, 함승경, 김영지 (2017). 세월호 침몰 사건의 미디어 담론 분석. 한국언론정보학보, 83, 7-38.
김영욱 등은 세월호 사고 이후 2년 동안 5개 일간신문의 세월호 보도 2만8558건을 분석했다. 먼저 기사 단어 행렬을 작성하고 공동출현 행렬로 전환한 다음 CONCOR 분석을 통해 4개의 군집으로 분류했다.
분석 결과 핵심 토픽은 세월호, 대통령, 정부, 참사, 국민, 대표 등의 순이었다. 중심성이 높은 단어는 세월호, 대통령, 정치, 정부, 국민, 우리 사회, 대표, 사람, 참사 등의 순이었다.
시기별로도 차이가 드러났다. 구조 수습기에는 ‘정부 책임’, ‘참사’, ‘구조’, ‘원인조사’ 담론이 구성되었다. 원인 책임 규명기에는 정치적 공방, 참사, 원인조사 등이 핵심이었다면 사후 대책기에는 정부 책임, 정치적 공방 등이 부각됐고 특별법 이행기에는 사회적 책임이, 특조위 활동기에는 정치적 공방, 포스트 세월호 등이 담론을 형성했다.
보수 성향 신문에서 사회적 책임을 강조한 반면 진보 성향 신문들이 원인 조사와 아이를 강조한 것도 흥미로운 대목이다. 보수 신문들은 사고로 규정했고 진보 신문들은 참사로 규정한 것도 중요한 차이다.
29. 김용학, 김영진, 김영석 (2008). 한국 언론학 분야 지식 생산과 확산의 구조. 한국언론학보, 52(1), 117- 140
김용학 등은 한국언론학회의 한국언론학보에 1995년부터 2005년까지 실린 논문 514건의 인용 문헌 정보를 대상으로 인용 네트워크의 구조를 분석했다. 수작업으로 입력을 했고 동명 이인과 비슷한 제목의 논문을 구별하기 위해 띄어쓰기를 제외하고 12byte를 합쳐서 고유성을 확보했다. 여기서 네트워크 노드는 연구자가 아니라 논문이 된다.
이 연구에서는 핵심어를 제목에서 추출했고 SAS IML을 이용해 행렬 자료로 변환했다. 네트워크 분석은 Pajek 1.12와 UCINET 6.57, Netminer 2.6을 사용했다.
분석 결과 514건의 논문에 피인용된 문헌은 1만8587건, 평균 39.9건이었다. 인용된 논문의 평균 연도는 게재 시점을 기준으로 7.6년이었다. 평균 8단계를 거치면 대부분의 논문이 서로 연결돼 있는 것으로 확인됐다. 이른바 좁은 세상 네트워크를 이루고 있는 것이다. 평균 피인용 회수는 1.11건, 척도 없는 네트워크(scale free network)를 구성하고 있는 것으로 나타났다. R2가 0.98로 거의 완벽하게 로그로그 선형 관계를 나타내고 있는 것으로 확인됐다. 이른바 20 대 80의 법칙이 언론학 분야 논문에도 적용되고 있다는 이야기다.
핵심어 블록은 TV와 보도, 미디어와 시장, 방송 산업, 광고, 정치, 커뮤니케이션 등이었다. 인터넷 미디어 관련 논문들이 인용 네트워크와 핵심 네트워크의 중앙에 자리잡고 있다는 사실도 이 논문이 밝혀낸 사실이다.
30. 김영욱, 함승경, 김영지, 최지명 (2017). 사회 쟁점에 대한 비판적 담론 분석. 커뮤니케이 션 이론, 13(4), 40-91
토픽 모델링이 공출현 어휘들을 통해서 텍스트의 주제를 파악하는 분석법이라면 언어 네트워크 분석은 텍스트에 존재하는 단어 사이의 관계를 부호화하고 연계된 단어들 사이의 관계를 분석하는 방법이다. 언어 네트워크 분석은 메시지를 구성하고 있는 단 어와 그들이 연결되는 패턴을 분석하여 메시지가 가지고 있는 본연의 내용구조를 파악할 수 있고, 텍스트를 해체한 후 이를 다시 조합해서 텍스트에서 전달하고자 하는 행간의 의미를 밝힘으로써, 텍스트가 전달하고자 하는 의미를 파악하는 데 유용하다. 특히 언어 네트워크 분석 중에서 구조적 등위성 분석은 노드 관계 유형의 유사성에 따라 집단을 구분하는 법으로 클러스터 분석과 수렴 상관관계(CONCOR: CONvergent CORrelation) 분석으로 나뉜다. 수렴 상관관계 분석은 노드 간 관계 패턴의 유사성을 측 정해서 군집을 구분하는 방법으로 먼저 피어슨 상관관계에 근거해 인접 행렬 데이터로부터 상관 행렬을 만든다. 그리고 이 상관 행렬을 반복적으로 계산하게 되면 +1 또는 -1의 값을 가지는 블록이 만들어지는데, 이때 분할 횟수(depth of splits)에 따라 군집의 수가 결정된다.
김영욱 등은 이 연구에서는 사드배치 관련 담론을 분석했다. 5개 일간신문의 기사 7018건을 크롤링해 149만여 건의 명사를 추출했고 페어 클라우의 분석 틀을 활용해 LDA – UCINET – CONCOR 분석으로 군집을 분류했다.
분석 결과 대중 관계, 한미 논의, 동북아 지정학, 북한 핵 등의 주제를 추출했고 언론사마다 선호 주제가 다르다는 사실을 확인할 수 있었다.
조선일보와 동아일보, 중앙일보 등은 미사일 방어와 북핵 제제 등의 주제를 많이 언급했고, 한겨레와 경향신문은 미사일 방어와 지역 갈등 등의 주제를 많이 언급했다.
언어 네트워크의 수렴 상관관계 분석을 통해 담론적 실천을 분석한 결과 보수 신문에서는 위협 담론에서 대응 담론으로, 안보 동맹 담론에서 정보 동맹 담론으로, 경제 보복 담론에서 사드 후폭풍 담론으로 담론적 실천을 형성했다. 반면 진보 신문에서는 MD 편입 담론에서 군사 주권 담론으로, 안보 외교 담론에서 평화 협력 담론으로, 사드 공방 담론에서 공론화 담론으로 담론적 실천을 형성했다.
이 연구는 비판적 담론 분석 연구를 양적 연구 방법과 결합했다. 방대한 데이터를 분석해 담론 생산과 변화, 이데올로기의 재현 등 담론의 다양한 층위를 분석했다는 데 의의가 있다.
31. 홍성철, 이완수 (2020). 뉴스 포털 〈네이버〉에 게시된 범죄사건 재현과 프레임 분석. 언론과학연구, 20(2), 256-293
홍성철 등은 2년 분량의 네이버 주요 뉴스에 오른 범죄 사건 가운데 7개를 선정해 1326건의 기사를 대상으로 4명의 코더가 내용 분석을 실시했다. 각각의 사건 기사는 1200~3200건 정도였고, 이를 시간 순으로 나열한 다음 매 10번째 기사를 선택해 분석했다.
분석 결과 일화적 프레임이 많았고 범죄를 흥미 위주로 보도하고 있다는 사실이 확인됐다. 선정적인 표현이 과도하게 많이 사용됐고 프라이버시 침해도 많았다. 범죄 유형에 따라 내용과 프레임에 차이가 있었고 매체 유형에 따라서도 달랐다. 근본적인 변화나 개선 보다는 선정적이고 흥미 위주의 보도에 머물러 있다는 사실이 이 연구로 드러났다.
32. 오세욱 (2017). 포털 뉴스 배열이력 분석: 네이버와 다음을 중심으로. , 3권 1호, 1-13.
오세욱은 2016년 5월 한 달 동안 네이버와 다음의 기사 배열 이력을 수집했다. 각각 네이버 PC는 3686건, 모바일은 5845건, 다음은 1만1984건이었다.
데이터 크롤링을 위해 오픈소스 웹 수집 프레임워크인 스크래피를 파이썬에 설치해 전수를 긁어오는 방식을 활용했다.
분석 결과 네이버 PC 기준으로는 연합뉴스가 전체 기사의 28.88%를 차지했고 뉴스1과 뉴시스가 뒤를 이었다. 다음 역시 연합뉴스가 31.24%, 통신 3사 합계가 48.24%를 차지했다. 네이버 PC에 게재된 기사 가운데 오프라인 신문에 게재된 기사가 17.8%에 그쳤다는 사실도 흥미롭다.
이 연구에서는 KoNLPy를 활용해 내용 분석을 실시했는데, 가장 많이 사용된 단어는 날씨와 북한, 구조조정 순이었다.
33. 양혜승 (2020). 40년이 흐른 지금, 언론은 5·18을 어떻게 소환하는가? : 텍스트 마이닝 기법을 활용한 조선일보, 한겨레, 광주일보 기사 분석. 지역과 커뮤니케이션, 24(2), 4-28
양혜승은 5.18 관련 보도의 주요 주제와 비중을 살펴보기 위해 빅카인즈를 활용해 4703건의 기사를 수집하고 이 가운데 조선일보 505건, 한겨레 1340건, 광주일보 2344건의 기사의 제목을 분석했다.
앙혜승에 따르면 제목은 기사 본문에 대한 압축과 요약으로 저널리즘에서 독립적으로 중요한 위치를 차지하며 독자들에게 영향력을 행사한다. 제목으로 기사를 분석하는 연구의 한계를 거론할 수도 있지만 권호천에 따르면 제목은 보도 방향과 관점 태도 등을 유추할 수 있는 지표가 된다. 실제로 기사에서 빈출 단어를 추출해 텍스트 네트워크 분석을 실시한 기존 연구에서 본문이 아니라 제목만 분석한 경우도 많다.
이 연구에서는 LDA 토픽 모델링 기법을 활용했다. 형태소 분석을 통해 추출한 단어는 5161개, TF-IDF 0.7 미만으로 나타난 단어를 제고하고 여, 야, 청, 군, 미 등의 단어를 여당, 야당, 청와대, 군부, 미국 등으로 유의어를 지정해 누락하지 않도록 했다. 최종적으로 4902개의 단어를 추출했다.
기계학습 알고리즘으로는 MCMC를 지정했고, 토픽수를 진상 규명과 오월 정신 승화, 역사 바로 세우기, 한국당 의원 망언 등 4개로 지정했다. 알파와 베타는 각각 12.5, 0.1이었다. 각각의 토픽에 따라 영향력이 높은 단어를 5개까지 추출했다. 이를 테면 2번 토픽의 주요 단어는 문재인, 오월, 정신, 전남도청, 민주 순이었다. 스프링맵이라는 툴을 활용해 상위 50개의 단어를 네트워크 구조화하고 시작화했다.
언론사 별로 살펴보면 조선일보는 상대적으로 진상 규명 보다는 한국당 의원의 망언을 중점적으로 다뤘고 광주일보는 오월 정신의 승화를 더 많이 다뤘다. 빈출 단어는 조선일보와 한겨레가 문재인, 광주일보는 전두환이었다.
이 연구는 조사 대상이 3년이고 언론사가 3개 뿐이라는 데서 아쉬움이 있다. 분석 대상을 본문이 아니라 제목에 한정한 것도 이 연구의 한계다. 양혜승은 이 연구에서 토픽 모델링 기법이 고전적인 내용 분석 방법과 비교해서 연구자의 주관적 판단을 최대한 배제할 수 있지만 토픽의 개수를 지정하는 등의 작업에서 연구자의 자의적 판단이 개입되는 부분 또한 존재한다고 지적했다. 주관적 판단이 개입되지 않는다고 해서 연구의 타당성을 제고한다고 보기도 어렵다.
34. 방한솔, 문호석 (2019). 텍스트마이닝을 이용하여 텍스트의 주요 토픽을 시계열적으로 표현하는 방법론 연구. 한국데이터정보과학회지, 30(6), 1259-1276
방한솔은 토픽모델링을 활용한 연구의 한계를 다음과 같이 지적한다. 첫째, 시간 정보를 고려하지 않고 토픽 모델링을 실시하면 시기별 특성을 반영할 수 없다. 둘째 토픽을 몇 개로 정할 것인지가 매우 중요하다. 남춘호에 따르면 토픽 수는 렌즈의 선택과 같다. 전체적인 조망이 필요할 때는 소수의 토픽을 묶어서 망원렌즈처럼 활용하고 세밀한 관찰이 필요할 때는 다수의 토픽을 추출해 현미경처럼 활용할 수 있다. 그러나 그 구분이 명확하지 않고 보통은 자의적 판단에 의존한다. 셋째, 대표 단어를 몇 개로 설정할 것인가도 중요하다. 역시 기준은 없지만 합당한 근거를 마련해야 한다.
텍스트 마이닝 연구는 데이터 수집과 데이터 프로세싱, 텀-도큐멘트 매트릭스(TDM), 토픽 모델링의 네 단계로 진행된다. 이 연구에서는 대표 단어를 선정하는 방법으로 동일 출현 확률을 적용했다. TF-IDF로 가중치를 적용해 단어 빈도를 구했고 LDA 모델을 적용해 주요 토픽을 선정했다. 토픽 수 선정을 위해서는 CaoJuan2009와 Deveaud2014 방법을 적용했다. 또 시계열 분석을 위해 시기별로 대표 단어의 빈도수를 정리해서 시계열 변화를 확인했다.
이 연구에서는 2018년 한 해 동안 네이버 뉴스에서 제목에 북핵이 포함된 기사 694건을 분석했다. 추출된 단어는 북한, 대통령, 미국, 비핵화, 문제, 북핵, 한반도 순이었다.
토픽 수를 결정하는 방법으로 Cao등의 방법은 WSS(whthin sum of square) 값을 기준으로 토픽 수가 늘어날수록 결과값이 작아지고 Deveaud 방법은 BSS(between sum of square) 값을 기준으로 토픽 수가 늘어날수록 결과 값이 커진다. 두 가지 방법에서 공통적으로 나타난 기울기 변화 지점을 찾은 결과 10개가 최적이라는 결론을 얻었고 10개의 토픽을 대상으로 LDA 모델 분석을 통해 출현 빈도에 따라 상위 25개 단어들을 추출했다. 토픽 마다 제목을 만드는 것은 연구자가 직접해야 한다.
이 연구에서는 특히 토픽의 월별 관심도를 파악하기 위해 출현 확률 상위 50%에 해당하는 단어의 빈도 수를 정리해서 토픽-문서 행렬을 만들기도 했다.
군집 수를 결정하기 위해 군집의 제곱합인 WSS의 변화를 그래프로 그린 다음 elbow point에 해당하는 3개의 군집으로 결정했다. 그 다음 tsclust 방법으로 비슷한 토픽을 군집으로 묶었다. 10개의 토픽을 3개의 군집으로 분류한 다음 군집의 이름을 결정했다.
35. 최현종 (2020). 토픽 모델링을 이용한 인공 지능 관련 신문 기사의 보도 경향 분석. 한국디지털콘텐츠학회 논문지, 21(7), 1293-1300
최현종은 빅카인즈에서 인공지능으로 검색한 결과 11만3832건의 기사를 토픽 모델링 기법으로 분석했다. 데이터 과학 프로젝트에서 이용하는 OSEMN 프레임 워크에 따라 진행했다.
제목의 단어 빈도를 연도 별로 추출한 결과 분기 보고, 전자, 영업이익, 코스닥 등의 단어가 높은 빈도로 나타났다. 이를 LDA 알고리즘으로 토픽 모델링을 한 결과 4차 산업혁명과 인공지능 관련 기술 등이 주요 토픽으로 추출됐다.
이 연구는 오히려 토픽 모델링 기법이 실제로 토픽을 제대로 반영하고 있는 것인가 하는 의문을 갖게 한다. 기사의 중요도를 감안하지 않았기 때문에 날씨와 주식 관련 기사가 상대적으로 많아 전체 결과를 분석하는 데 한계가 있었던 것으로 보인다.
36. 노설현 (2020). 토픽모델링을 활용한 4차 산업혁명의 이슈 분석. 한국디지털콘텐츠학회 논문지, 21(3), 551-560.
노설현도 빅카인즈로 4차 산업혁명 키워드를 검색해 4389건의 기사를 분석했다.
이 연구에서는 최적의 토픽 수를 결정하기 위해 perplexity를 측정해서 K값을 15로 설정했다. 분석 결과 인문학의 역할과 개인정보 규제 완화, 정부와 기업의 활동, 일자리 문제, 에너지 패러다임 전환 등의 토픽이 추출됐다.
37. 김민재 (2020). 언론은 가습기살균제 참사를 어떻게 재현했는가 : 보도 분석과 토픽 모델링을 통한 프레임 분석. 환경사회학연구 ECO, 24(1), 181-224
김민재는 가습기 살균제 보도의 시기별 특성과 이념적 지향에 따른 차이를 비교하기 위해 9개 언론사의 기사를 수집해서 토픽 모델링을 실시했다. KoNLPy를 개량한 cKoNLPy를 활용했고 명사+명사 형태의 bigram을 식별하고 단어를 정규화하는 전처리 작업을 진행했다. 젠심(gensim) 패키지의 LDA 모델로 토픽을 분류했다. 이 연구에서는 pyLDAvis를 통해 토픽을 20~32개까지 조정하면서 결과를 비교했고 최종적으로 토픽을 25개로 정했다.
토픽 모델링 결과는 검찰 조사와 정부 대책, 실내 공기, 특조위, 피해자, 예산, 공정거래위 등으로 나뉘었다. 이 연구는 토픽모델링과 연구자의 프레임 분석을 비교했는데 시민단체의 활동이 불매운동 토픽에만 나타난다거나 언론의 자성이나 기업의 부담 등의 프레임은 토픽 모델링에서 나타나지 않았다. 반면 보도 계기 분석과 프레임 분석을 합친 결과를 토픽 모델링에서 확인할 수 있었다.
38. 강범일, 송민, 조화순 (2013). 토픽 모델링을 이용한 신문 자료의 오피니언 마이닝에 대한 연구. 한국문헌정보 학회지, 47(4), 315-334
강범일 등은 18대 대통령 선거 보도에서의 언론사 논조를 비교하기 위해 기사를 크롤링하고 LDA 모델로 키워드를 추출했다. 샘플링을 3000회, 15개의 주제를 추출했다. 각각의 주제를 구성하는 20개의 단어를 추출하고 동시 출현 빈도에 따라 행렬을 구성했다. 군집화를 위해 PNNC 알고리즘을 적용했고 NodeXL을 이용해 시각화했다.
연구 결과 과거사와 정수장학회 등의 주제는 진보 성향 매체에서만 등장했다. 남북 관계는 보수 성향 매체에서 더 자주 등장했다.
경제민주화라는 주제의 네트워크를 분석한 결과 언론이 자신들의 논조에 유리한 이슈는 강조하고 불리한 이슈는 소극적으로 보도하는 경향성이 발견됐다. 네트워크 분석과 토픽 모델링을 결합한 것이 이 연구의 돋보이는 부분이다. 레이블링 작업에 연구자의 주관적 판단이 개입된다는 것은 한계로 지적된다.
39. 박대민 (2013). 뉴스 기사의 빅데이터 분석 방법으로서 뉴스정보원연결망분석. 한국언론학보, 57(6), 234-262
박대민은 사회연결망분석(SNA, source network analysis) 방법으로 언론 보도의 정보원 편향성을 분석했다. NSNA라는 자체 개발한 솔루션을 활용했다.
박대민에 따르면 빅카인즈에 저장된 기사 2900만 건의 용량은 360GB 밖에 안 된다. 박대민의 추정에 따르면 2013년 기준으로 기사 수는 12억 건, 문장 수는 120억 건이 넘을 수도 있다.
이 연구에서는 뉴타운 관련 기사 2239건 가운데 정보원이 포함된 기사는 1844건, 이를 정보원-기사의 행렬로 구성하고 연결정도 중앙성을 계산했다. 정보원 수는 321명이었고 박원순, 박원갑, 박상언, 함영진 순으로 나타났다.
40. 박대민, 김기남, 강남용, 서봉원, 하효지, 온병원 (2014). 저널리즘 가치에 기초한 알고리즘을 이용한 뉴스 시각화. 한국HCI학회 논문지, 9(2), 5-12
박대민 등은 NSNA(news source network analysis, NSNA)를 활용해 취재원을 노드로 기사를 엣지로 설정하고 연결망을 분석했다. 정보원을 식별하기 위해 자연어 처리를 통해 인용문을 추출하고 인명 사전을 교차 비교하면서 매칭했다.
이렇게 확보한 정보원 데이터를 정보원 가중치와 문장 가중치, 기사 가중치를 적용해 순위를 부여하고 시각화하는 방법을 소개했다.
41. 최정균, 진서훈, 최종후. (2017). 텍스트 마이닝 기법을 이용한 언론사별 보도 변화 양상 탐구. , 19(5), 2509-2522.
최정균 등은 세월호 보도 분석을 위해 텍스트 마이닝 기법을 활용했다. Python 3.6.1 환경에서 html로 작성된 문서들을 파싱(parsing)하기 위한 BeautifulSoup라는 라이브러리를 이용했고 태그의 텍스트를 수집했다. KoNLP로 형태소 분석을 한 결과 참사 직후 기사에서는 정부와 오전, 오후, 구조, 안전, 이후, 국민 순으로 나타났다. 세월호 특별법 논의가 한창이던 2014년 8월에는 국회, 야당, 요구, 대통령, 특별법 순이었다. 2015년 5월에는 모금액, 행사, 활동, 사용 순이었다.
LDA 분석을 실시한 결과 경향신문과 한겨레에서는 ‘규탄’, ‘책임’, ‘무능’, ‘촉구’ 등의 단어가 등장하지만 동아일보에서는 ‘추모’, ‘행사’ 라는 단어가 등장했다. (LDA 설명이 잘 돼 있는 듯.)
42. 김도우, 구명완 (2017). Doc2Vec과 Word2Vec을 활용한 Convolutional Neural Network 기반 한국어 신문 기사 분류. 정보과학회논문지, 44(7), 742-747
워드 투 벡터는 단어의 출현 빈도와 상관 관계를 벡터화한 것이다. 김도우 등은 이 연구에서 워드 투 벡터에 도큐먼트 투 벡터를 추가 적용하는 방법으로 분류 효율을 높일 수 있다는 사실을 입증했다.
43. 현기득, 정낙원, 서미혜 (2020). 포털 뉴스와 댓글에 대한 정파성 지각이 포털 뉴스 신뢰, 영향력 지각 및 선택적 노출에 미치는 영향 : 보수와 진보 이용자의 차이를 중심으로. 한국언론학보, 64(4), 247-288
읽고 싶은 것만 골라 읽는 이른바 선택적 노출(selective exposure) 현상을 보수와 진보로 나눠서 분석한 연구다. 이 연구에서는 네이버와 다음이 비교적 중립적이라는 판단 아래 진보와 보수의 이용자들이 각각 적대적 정파성을 갖게 된다는 가설을 입증했다. 네이버에서는 ‘조국 구속’이, 다음에서는 ‘조국 수호’가 인기 검색어로 떠오른 것도 이러한 적대적 편향성 지각이 반영된 결과라는 분석이다.
진보적 성향의 이용자들은 네이버가 보수적이라고 판단할 것이고 보수적 성향의 이용자들은 다음이 진보적이라고 판단할 것이라는 게 이들의 가설이다. 이들은 1600명을 상대로 온라인 설문을 실시해서 각각 자신의 정치적 성향과 두 포털 뉴스에 대한 신뢰도를 평가하도록 했다. 스스로를 각각 진보와 보수라고 답변한 두 집단을 비교한 결과 보수는 다음을, 진보는 네이버를 편향적이라고 판단한다는 사실을 확인할 수 있었다. 또한 보수 성향의 이용자들은 네이버에 자신의 견해와 다른 기사가 실려도 네이버에 대한 신뢰가 크게 달라지지 않지만 진보 성향의 이용자들은 다음에 자신들의 생각과 다른 기사가 실릴 경우 다음에 대한 신뢰가 떨어진다고 답변하는 경우가 많았다. 댓글도 적대적 의견 지각이 진보의 경우가 더 큰 것으로 나타났다.
이 연구는 정확한 가설과 연구 과제에 기초해서 설문조사를 실시하고 가설을 확인했다. 상당수 이용자들이 포털을 단순히 뉴스의 수집과 배포를 넘어 정파적 갈등이 다시 매개돼 반영되는 공간으로 의식하고 있다는 결론을 끌어냈다.
구체적으로 변인을 통제하기 위해 보수적 성향의 이용자가 진보적 논조의 기사와 댓글을 맞닥뜨렸을 때와 진보적 성향의 이용자가 보수적 논조의 기사와 댓글을 맞닥뜨렸을 때를 각각 구분해서 반응을 비교했다.
44. 김용학, 김영진, 김영석 (2008). 한국 언론학 분야 지식 생산과 확산의 구조. 한국언론학보, 52(1), 117- 140
복잡계 네트워크 이론으로 언론학 분야 논문의 관계를 분석한 논문이다.
김용학 등은 한국언론학보에 실린 논문 514건과 여기에 인용된 논문 1만8758건의 인용 관계를 분석해 이들 논문들이 좁은 세상 네트워크의 특성을 나타내고 있다는 사실을 밝혀냈다. 인용된 문헌들이 8단계 만에 서로 연결됐고 멱함수의 구조를 나타냈다. 인터넷과 모바일 커뮤니케이션을 다룬 논문들이 네트워크의 중심에 놓여있었다.
이들은 분석을 위해 직접 자료를 입력했고 Pajek과 UNICET, Netminer 등으로 네트워크 분석을 실시했다. 평균 인용 문헌은 39.9건, 평균 경로 거리는 7.9건, 구성 집단은 50개로 나타났다.
|
leejeonghwan.com audio
 |



