
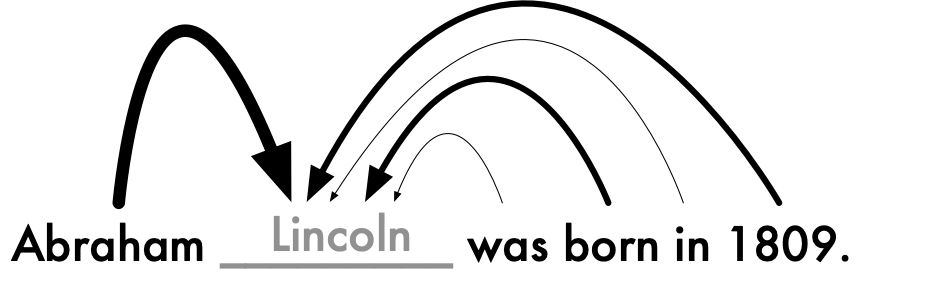
“Abraham Lincoln was born on April 4, 1809 in Springfield, Illinois. (에이브러햄 링컨은 1809년 4월4일 일리노이주 스프링필드에서 태어났다.)”
이 문장은 세 가지 이유에서 정말 놀랍다. 첫째, 에이브러햄 링컨이라는 사람이 1809년에 태어난 미국 사람이라는 사실을 근거로 만든 문장이다. 둘째, 사람이 쓴 것처럼 완벽한 문장처럼 보인다. 셋째, 그러나 이 문장은 완벽한 거짓 문장이다.

지난 2월, 일론 머스크가 투자한 오픈AI(OpenAI)가 GPT-2라는 자연어 처리 모델 아키텍처(natural language processing model architecture)를 공개했을 때 많은 사람들이 충격과 공포에 휩싸였다. GPT-2는 800만 개의 웹 페이지와 15억 개의 단어를 학습해 문장을 생성하는 훈련을 했다. ‘에이브러햄 링컨’이라는 단어를 주면 그 다음에 자연스럽게 이어질 단어를 나열하면서 문장을 완성시키는 것이다.
실제로 링컨은 4월4일이 아니라 2월12일, 일리노이주 스프링필드가 아니라 켄터키주 호겐빌에서 태어났다. 스프링필드는 링컨이 처음 변호사 생활을 시작한 곳이다. 그러니까 완벽하게 근거 없는 단어는 아니고 적당히 관련 있는 단어를 추측하고 확률에 근거해 문장을 조합하는 것이다. 가짜 문장이지만 논리적으로 그럴 듯 하고 개연성도 있고 언뜻 보면 완결된 문장처럼 보인다. 인공지능으로 완벽한 가짜 뉴스를 만드는 시대가 된 것이다.

오픈AI는 당초 “너무 위험해서 공개할 수 없다(too dangerous to be released)”고 밝혔지만 9개월 뒤인 지난 11월, 풀 버전을 공개했다. 다섯 가지 이유에서다. 첫째, 사람이 쓴 문장과 구분이 어려울 정도로 완성도가 높아졌고, 둘째, 잘못된 용도로 사용하지 않도록 관리할 수 있고, 셋째, 가짜 뉴스 탐지가 중요한 과제가 됐고, 넷째, 잘못 사용될 우려가 크지 않다고 판단했고, 다섯째, 좀 더 연구가 필요하다고 판단했기 때문이다.
우리는 완전히 다른 차원의 가짜 뉴스의 등장을 목도하고 있다. 이를 테면 뉴욕타임스 기사 제목을 불러와서 가짜 본문을 만들고 가짜 본문으로 가짜 제목을 만들어내는 것도 가능하게 된다. 마음만 먹으면 아무런 비용 없이 한 시간에 수천 건의 가짜 뉴스를 쏟아낼 수 있다. BBC 스타일이나 워싱턴포스트 스타일로 가짜 뉴스를 만들 수 있고 헤밍웨이나 조지 오웰 스타일의 문장을 만들어 낼 수도 있다.
인공지능 가짜 뉴스의 등장과 관련해 몇 가지 생각해 볼 부분이 있다. 이걸로 뭘 할 수 있을까. 누군가가 링컨의 생일이나 출생지를 속여서 얻는 게 있나? 대량으로 반복적이고 지속적으로 정보를 교란하기 위한 목적이라면 효과적일 수도 있겠지만 실제로 이런 가짜 뉴스가 검색 엔진에 랭크되지 않는다면 큰 의미가 없다. GPT-2 역시 도구일 뿐 어떤 의도를 갖고 어떤 잘못된 정보를 전달하느냐의 문제다.
최근의 연구에서는 인공지능으로 만든 가짜 뉴스를 인공지능으로 탐지하는 기술도 등장했다. 꿩 잡는 게 매라고 한다. 하버드대학교와 IBM 왓슨연구소가 공동 개발한 GLTR(Giant Language Model Test Room)이라는 기술은 단어의 예측 가능성이 높고 불확실성이 낮을수록 인공지능이 작성한 콘텐츠일 가능성이 높은 것으로 본다. GPT-2가 아무리 감쪽 같은 가짜 뉴스를 만든다고 한들 결국 확률 게임을 하고 있는 것 뿐이라는 가정에서 출발한다.
실제로 GPT-2가 작성한 가짜 뉴스를 테스트한 결과 실험자들이 GPT-2의 가짜 뉴스를 54%의 비율로 구별했지만 GLTR의 도움을 받으면 이 확률이 72%까지 높아지는 것으로 나타났다. 문제는 인공지능의 도움을 받더라도 여전히 28%의 가짜 뉴스를 구별하지 못한다는 것이다. 그리고 GPT-2가 의도적으로 불확실성이 높은 단어를 끼워 넣을 경우 이런 필터를 우회할 수 있을 것이라는 가정도 가능하다.

GPT-2는 가짜(유사) 가짜 뉴스라고 할 수 있다. GPT-2는 무시무시하지만 아직까지 실험실 밖에서는 영향력이 크지 않다. 링컨의 생일 따위는 사실 아무도 관심이 없다. 진짜 가짜 뉴스는 훨씬 복잡하고 은밀하게 작동한다. 오히려 GPT-2가 무서운 것은 진짜 뉴스의 영향력과 가치를 떨어뜨릴 가능성 때문이다. 우리가 두려워할 것은 진짜를 흉내내는 인공지능이 아니라 허위의 조작된 정보가 진짜를 압도하는 권력을 갖게 될 가능성 때문이다.
알고리즘 기사(automated news)와 알고리즘이 만드는 가짜 뉴스(automated fake news)는 동전의 양면과도 같다. 로봇 기사가 미리 설정된 문장의 조합에 데이터를 끼워넣는 방식이라면 GPT-2가 만드는 가짜 뉴스는 키워드만 주면 문장을 만들어 낸다. 데이터가 진짜냐 가짜냐의 차이만 있을 뿐이다. 만약 GPT-2에 팩트 체크 알고리즘을 집어넣고 팩트의 경중을 반영하고 정확도를 높인다면 본격적인 알고리즘 저널리즘도 가능하게 될 것이다.
인공지능으로 가짜 뉴스를 잡아낼 수 있을 거라는 기대는 아직까지는 환상이다. 오히려 가짜 뉴스는 알고리즘이나 데이터의 문제가 아니라 우리가 진실을 어떻게 다루는가에 대한 철학적인 문제(philosophical question of how we deal with the truth)라고 할 수 있다. 기술의 도움으로 거짓 주장과 잘못된 정보에 대한 투명성을 높일 수 있겠지만 가짜 뉴스의 문제는 근본적으로 언론의 신뢰 회복과 비판적 사고의 강화로 풀어야 한다.
인공지능으로 가짜 뉴스를 쏟아내는 시대, 여전히 출처 확인은 매우 중요하다(그렇지만 결코 쉽지 않다). 어디까지가 진짜고 어디서부터 가짜인지 구분하기도 쉽지 않다. 근본적인 해법은 모든 뉴스를 의심하고 검증해야 한다는 것이다. 평판의 시장이 작동하게 만들어야 한다. 가짜 뉴스를 막는 것 못지 않게 바로잡는 것도 중요하다. 진짜 뉴스를 강화하는 것 외의 가짜 뉴스의 해법이 있을 수 없다.
(김소영 교수님 수업 과학기술정책 기말 과제.)
참고 자료.
https://openai.com/blog/better-language-models/
https://openai.com/blog/gpt-2-1-5b-release/
http://gltr.io/
https://horizon-magazine.eu/article/can-artificial-intelligence-help-end-fake-news.html
https://medium.com/@ageitgey/deepfaking-the-news-with-nlp-and-transformer-models-5e057ebd697d
|
leejeonghwan.com audio
 |



